Performance Validation Now Includes GPU Throughput and AI Inference Latency
The core question -- how close to maximum theoretical performance are your applications? -- has expanded. AI inference workloads have added GPU utilization, model load time, tensor processing throughput, and batch queue depth to the performance validation equation. An organization running large language models or real-time computer vision cannot validate performance by measuring bandwidth and CPU alone. GPU memory saturation, PCIe bus contention, and NVLink fabric latency are now first-order performance constraints that directly impact end-user experience.
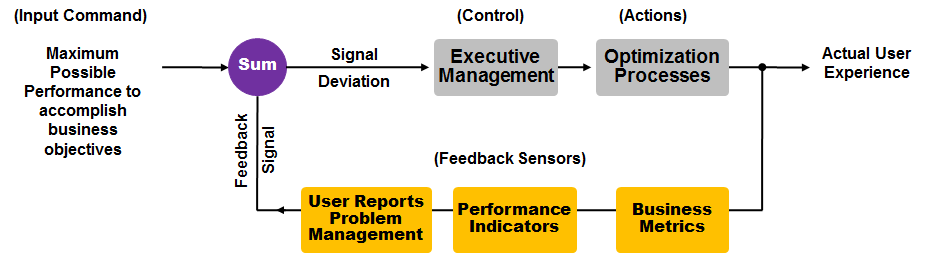
The performance validation servo-loop still applies: set your desired response time, measure the actual user experience, calculate the deviation, and act. But the feedback sensors now include GPU telemetry, inference latency percentiles, and token-per-second throughput alongside traditional network round-trip and server response metrics. Organizations that skip this validation step deploy AI workloads blind -- and discover performance gaps only when production users complain. These themes of AI infrastructure performance and convergence with traditional network diagnostics are explored on the Morpheus Cyber podcast.